
Groups
In my last blog, I showed what happens if you are hit by bad news. In a lot of cases, it is hard to re-use the old, while maintaining trust, as it is often unclear how deep the infection went.
When it is time to rebuild, the first step is to create a framework for trust, to ensure the people rebuilding are indeed the people you want to be rebuilding. Instead of some adversary that is happy to help out re-creating a backdoor. In order to do this, you need to set up a framework of groups, roles and rights, which is relatively static and can be re-created automatically.
In my blog post on Enterprise IT I presented a model to define the groups you can identify:
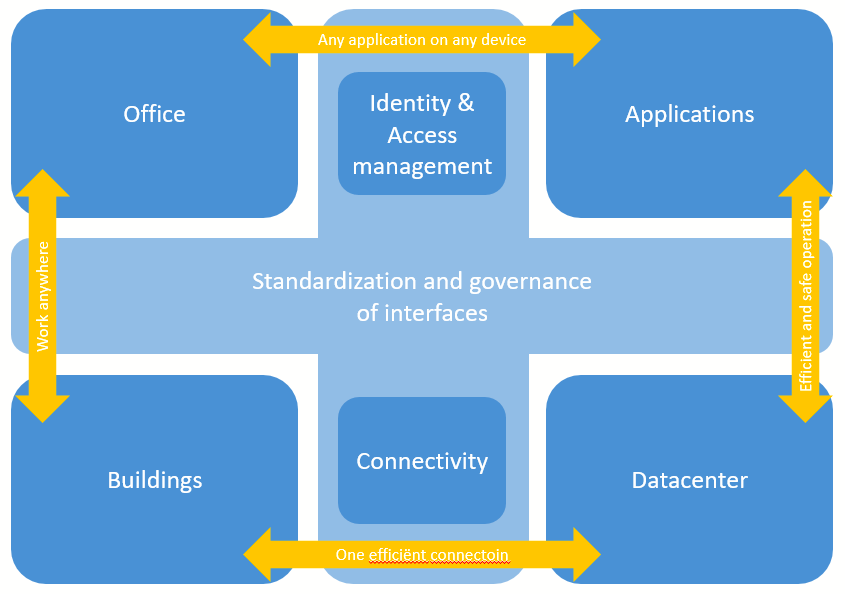
for each or the dark blue blocks, you have a Domain Architect. The Domain architect is part of the enterprise architecture team and makes sure all developments in an architecture domain align with the developments in other domains.
Within each Domain, you have one or more Platform Designers, like a network architect, a VMware Architect or a Storage Architect in the datacenter Domain. The main responsibility of this Platform Designer is to lead all development efforts and make sure all developments in the domain are aligned with the Domain Architect and the other Platform Designers. As such you could view the Domain architect as the “architecture lead” for the Technology domain and the Platform Designers as the engineering team to make it happen. Together they author the High Level Design for the platform, explaining not only the solutions to be engineered, but also the process that has been followed and decisions that have been made to come to those solutions.
This role is purposely separated from the team lead role or HR role. You want your Platform Designers to be able to firmly disagree with the Domain Architect without repercussions for their carreers. In organizations where they do not make this separation, you often see stagnating innovation…
The Platform Designers cannot do this alone. The technical knowledge required quickly goes too deep and therefore a specialist is required to translate the engineering guidelines to designs and implementations. It is important that both Platform Designers and Platform Specialist form a close-knit team, where the designer focuses more on the structure for the platform and the Platform Specialist more on the operational aspects. When there are issues, the Specialist is probably the first to hear is, but the Platform Designer should want to be a close second. As a team, they are responsible for the Low Level Designs for the platforms.
Operations is done by Operators. Together with the Platform Specialist, they make sure everything runs smoothly.
You may wonder why changes are not mentioned. There is a very simple reason for this. Changes are no operational task and should not be performed manually. These should be automated, as this is the only way to trust that changes executed are fully tested before execution. This separation between RUN and CHANGE is one of the major drivers for regaining trust.
This leads to a structure like the one below:

As you can see, the structure is easy to understand and easy to implement. It can be nested several levels deep when the complexity of the underlying platform requires this.
The picture above is implemented in the CICD-Toolbox in Keycloak. This is a playground where I test implementations of the stuff I blog about. I chose to use Keycloak due to the extensive documentation, the fact that it is Open Source and that it is possible to get support from RedHat when needed.
Roles
The roles that need to be implemented depend on the application that is to be put under IAM. In order to get started, let’s take a look at some applications you’ll likely find in a CICD pipeline that will be used to re-deploy your infra:
- git (source code/script/workflow repository, the workhorse for the developer)
- Jenkins (orchestrator, does most of the boring work)
- Sonatype Nexus (curated source of updates and report store)
The roles defined should be application specific, so they are only announced to the client requesting access on behalf of a user. This prevents rogue clients from silently learning all available roles.
git
Git is your repository where all the workflows and other scripts are stored. As can be expected, not everyone has access to each repository and thus every repository in git is subject to IAM.
In general, rights are read, write and admin. As you want to be able to set this on a per-repository basis, this implies that there needs to be a role for each repository right. So for the NetCICD repository, this boils down to:
- git-netcicd-read
- git-netcicd-write
- git-netcicd-admin
You can go further in defining roles, but in general this will suffice.
The reason for the prefix git- in the role name is to be able to distinguish between roles with identical names for different applications.
These roles need to be defined in git and associated to the proper repository. NetCICD in this case. There may be way more complex group mappings, teams, organizations and other stuff in your git tool, but just keeping it simple also makes your IAM system manageable.
Jenkins
Jenkins has quite a well defined system for defining local roles:

This implies you can define roles locally. Luckliy all kinds of pattern matching is possible. When a user comes to the system using IAM, it will provide the role(s) assigned to the user, which will become properties of the user in Jenkins.
These roles can easily be linked to rights:

By linking roles to specific rights, the user can execute what is required and permitted.
Understanding and properly closing Jenkins can be tricky though. Especially with remote agents like those used in NetCICD, where a Jenkinsfile is used to define what Jenkins is going to do.
Sonatype Nexus
Just like Jenkins, Nexus lets you define local roles:

As you can see I have defined a Jenkinsagent role for a Jenkins Agent running in some remote lab to be able to push test reports to Nexus. I provided this role with the right to push data to the NetCICD reports repository:

As you can see, these applications make it easy to work with single sign-on (provided you configure it correctly).
Configuration of the systems
In order to be able to work safely, you need to get the sources of these systems from the respective vendors. In order to rebuild quickly, I would use Docker Containers. Why? Simple: the vendor maintains a proper version of the software including the latest security patches in the Docker Hub. When you get the software from there, chances are small that the software is tainted.
Configuration must be done as code: after all, you want to know what is configured when you are rebuilding. That is why the configuration in the CICD toolbox uses shell scripts and the vendor provided CLI to configure all systems if possible. Where impossible, I used a configuration-as-code plugin, for example for Jenkins. This plugin is provided on the vendor site with many installs and badges that let you validate the code.
Even though it is tricky, we’ll have to keep our fingers crossed at this point, as we do not yet have something to validate against. If you cannot live with this, download the docker images, plugins and code beforehand, scan and validate it and run from removable media when required.
Next steps
In the Next blog, we’ll dive into more foundational stuff. Before we can make the configuration of Keycloak in order to make the magic happen, we need to make sure we can trust keycloak as a source and make sure no eavesdropping can occur. After that wel’ll go into detail on OIDC and JSON Web tokens, how they are used and their role in transferring information from user to application.


