There are many articles, blogs and webinars discussing how to configure the most exotic and interesting tools. But which tools do you actually need? Is there a best practice in setting up an environment for infrastructure automation? What does the physical setup look like, which choices need to be considered? A lot of questions, which I also encounter at my clients. Given that the outcome is often the same, I thought it would be useful to write down some considerations to think about.
What do you need?
“What do you need?” may be the most important question to consider. Depending on the size of your organization, there may be books and mandatory guidelines that must be followed. Using common sense you’ll come a long way, but often, somewhere along the line you’ll start making shortcuts that will bite you in the back later. So here are some of my personal best practices:
You need to separate production from management and SOC
The first and most important decision to make is to physically separate your production workloads from your management workloads. This way your management systems will survive when the production systems get compromised or run amok.
You need to separate IT management and SOC
If you consider that any IT organization WILL be compromised one day, it is wise to setup the IT management environment as if you are a big corporate. It may seem overkill, but if you cannot provide a post mortem to your managers, you’re history. And if it is bad enough, so is your company. Remember Diginotar?
In addition, during an attack, you want your SOC to be alive. When management systems are attacked, like in the Ukranian blackout case, you want your SOC to be able to trace what is happening and stop the attack if possible.
You need to separate development from production
This is always an interesting discussion. What is development and what is production? In order to make a proper division, consider that your production environment needs to be as independent as possible from testing. Up to a certain point.
For example, the network department needs to physically break stuff when testing. Like ripping out (fiberoptic or power)cables to test network convergence. This requires a physically separated test environment. The same is true for the hypervisor platform team. They need to physically see what happens if you shut down or rip out physical machines from a cluster.
However, while learning to respond to unforeseen events is good, in a carefully crafted test setup needed to validate how THAT environment responds to failures, it is not. So, if any team needs stability, they need to run on a production environment. This is for example true for the Hypervisor team. They to be on a production network segment that MUST be stable as not to pollute their testing.
Likewise, the test environment of an application team needs to run on a production compute and storage platform.
And here is the caveat. Dev, Test and Acceptance MUST be physically separated from production-Prod platforms. You must have a kill switch if for example your destructive penetration testing runs amok. But I said that before…
You need to separate front-end management systems from back-end management systems
Your management environment contains the “gold” of your organization. Anyone with access to the systems in the management domain has – in theory – access to that “gold”. As with any application, it is good and common practice to separate the front-end from the back-end.
The least you need to do is to create separate L2 domains/subnets. This way you can force that the front-end contains systems that can only be approached from the production environment, while the back-end systems can only be approached from the front-end systems or from separate management stations.
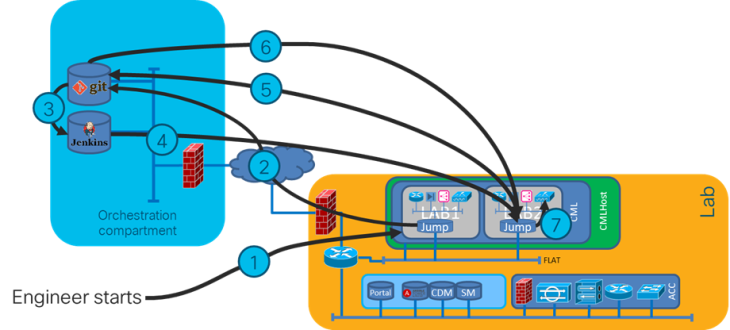
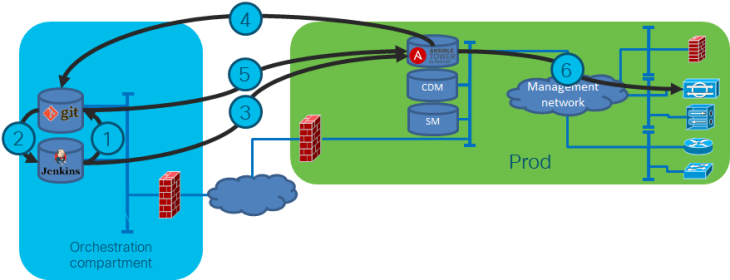
Another measure is to only have “slaves” as front-ends. Jenkins for example has such an option. And on the slave you can run other tools. This allows you to create a relatively standard slave setup, independent from the environment where you are using it. The dynamic part comes from for example Ansible playbooks stored in git. This is what I did when making the NetCICD platform.
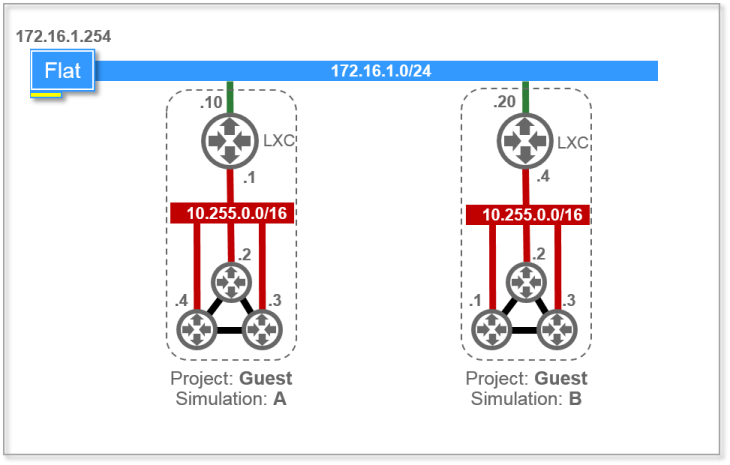
The challenge here is that these slaves are may be ephemeral machines that are getting their IP address from DHCP and need a key to connect. As you may want to have multiple of such environments, hardcoding IP addresses or keys is not possible and insecure. So, the master cannot connect to the slave, instead the slave needs to connect to the master.
This implies that before spinning up the slave, you need to generate a “landing zone” just before booting the ephemeral slave, pass the arguments to the slave, and let the slave connect. This allows for multiple slaves and as secrets are generated on the fly driven by the master, it is secure.
And it has a second advantage. It is easy to replace the slave with a new version. No configuration drift, just replace. This is the slave I use.
You need Access Control
Would you allow anyone to access your management stations? Would you want to add every user to every system? This is why you need Access Control. Role and Attribute based access control (RBAC/ABAC) has the advantage that access is no longer linked to a user but to a role and a group. You know that. But in general, people make it way to complicated. This is what I observe in teams at clients.
When users start at your organization, they get a function title, which is linked to the renumeration scheme of HR. In addition they become part of a few proceses. Those are the roles we are talking about. These roles are linked to the processes which in general do not change much. I generally see the following operational roles in an IT organization: Operators, Senior Operators/Specialists, Technical Architects and Domain architects. That seems like a not-to-overwhelming number of roles to manage.
Those roles are often present in multiple departments: network operators, Windows operators, Linux operators, etc. And network operators are part of the Network team, Windows operators are part of the Windows team etc. Call that a group and you’re done. Do not do more. It complicates stuff way beyond what you can fathom. Untangling takes ages. Maintaining two lists: easy.
Loose a role: rights gone. No longer in a group: rights gone. Can you have multiple roles? Yep. Can you be in multiple groups? Yep too. Is it smart? Well, as long as I do not have to manage it….
You need OTP and single use credentials
Given the experience of quite a few organisations with Mimikatz and other password and credential stealing exploits, there needs to be some mechanism to make sure you cannot steal al credential. One time passwords help, but sometimes people want Single Sign-on and so, these credentials are translated into some kind of token.
What I learned: do not do this in systems management roles. It may be nice for a user, but it is disastous for security. Log in from your jumphost every time.
And use a specialized tool for this. To me this is specialized stuff. Hire someone to help you out here.
You need a proper cost model
When reading the above, it seems like quite an investment to run your own IT. Still, there is a kind of sweet spot where running your own IT infrastructure is more cost efficient than using the cloud. I’ve been told that this lies around 1000 employees, but I cannot corroberate this number as I have not done this calculation myself.
In order for such a solution to not only be seen as a source of cost but as the cost of doing business, you need to have a proper cost model. This is the only way to make sure not all discussions are about why you did not go to the cloud.
The fact is that when internal IT infrastructure is done properly and you have enough scale, the cost of doing it yourself is actually lower than using the cloud. The cost of the cloud is only low for ephemeral workloads. If your applications are running 24×7, that advantage is gone.
With a proper cost model you can prove that. When you move a lot of workloads to the cloud, for example your dev and test, it takes longer to reach the point where your own infrastructure outprices the cloud. This makes management discussions on cloud efficiency vs. infrastructure cost a lot harder to win.
Is there a reference design for this?
So, how can you do all of this without investing the world? First, consider that most companies write these investments off in a period of 5 years (60 months). If you divide the investment by 60 and again by the number of managed devices, you’ll see that the additional cost per managed unit is relatively low. And if done properly, this is the cost of doing business, which you can prove with the cost model.
Most or all of the systems involved can be run as open source containers on a Kubernetes cluster. This saves you from building all kinds of reliability duplication. Instead, Kubernetes will do this for you.
By following the owner’s container releases on the Docker Hub, you do not have to build and maintain all these systems yourself. Store the configuration and data outside of the containers and you can rotate in and out as desired.
Maybe, some time, I’ll add a post with a reference design.
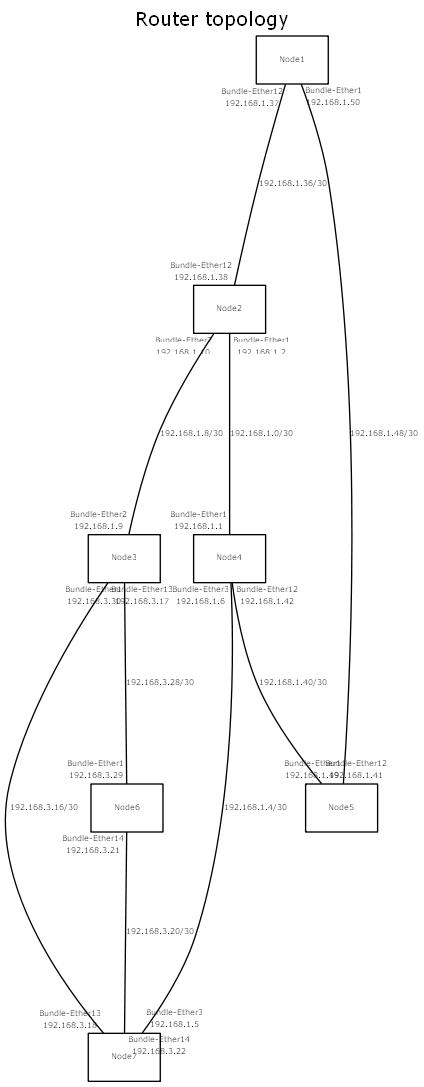
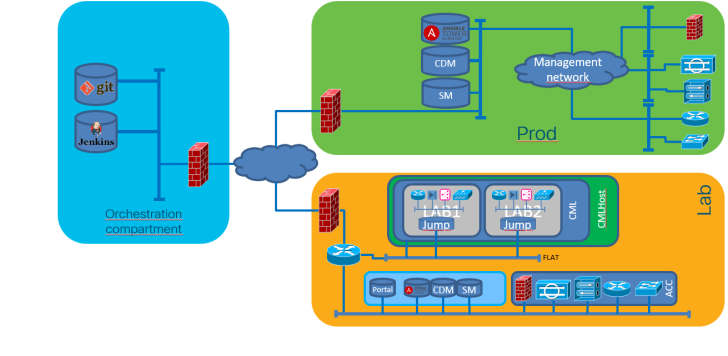 The NetCICD setup consists of three zones.
The NetCICD setup consists of three zones.